
Machine Learning:
Machine learning is a subset of artificial intelligence (AI) that focuses on how computers learn from (usually) large amounts of data. There is spectrum of machine learning that spans from relatively simple algorithms (linear regression) to complex (generative adversarial networks). At the heart of almost all machine learning processes are statistical algorithms – this is why some have termed more simple algorithms as statistical learning and reserved the machine learning category for more complex algorithms. The ultimate goal of all models is to continuously learn from data, and to improve performance as more data and experience is generated. Machine learning is responsible for many of the tasks included in our daily routines – it recognizes spam and automatically filters it from your email, helps Google return personalized search results, allows Netflix to offer recommendations based on your previous movie choices and preferences, directs Amazon warehouse robots and driverless cars, as well as training and directing virtual assistants like Alexa. It is also being deployed in the medical realm, especially within the field of Cardiology, which is why I will discuss it here.
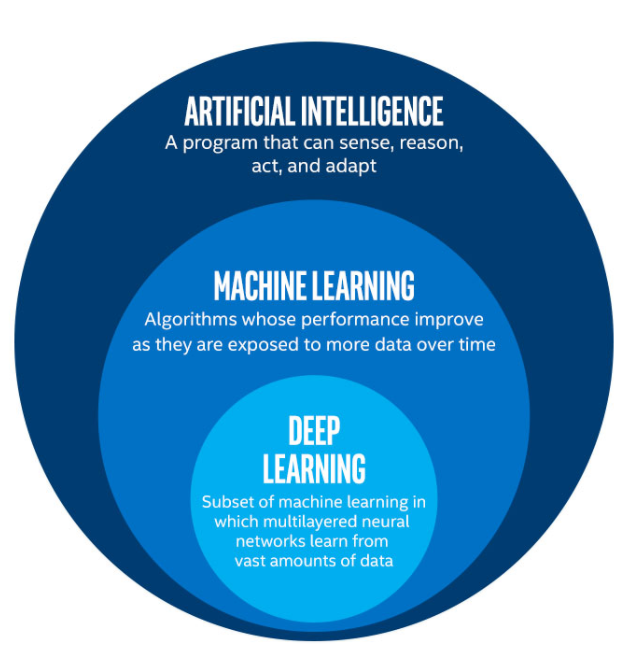
Machine learning can be broken down (roughly) into three main buckets: (i) supervised learning, (ii) unsupervised learning and (iii) reinforcement learning. I will focus mainly on the first two categories and provide some examples pertinent to the field of Cardiology.
Supervised Learning:
Supervised learning utilizes large ‘structured’ datasets in order to ‘train’ or develop predictive statistical algorithms. Structured means that the data is known and previously labeled in some way. For instance, if we are interested in predicting different factors that might be associated with developing heart disease over a lifetime, we could use a dataset that includes individuals where the outcome of interest (heart disease) is known – i.e. they have labels of ‘heart disease’ or ‘no heart disease.’ By exploiting this labeled dataset, we can feed this information to a machine learning algorithm which uses it to determine the features associated with individuals that have heart disease more often than individuals that don’t have heart disease. This is how a model would learn that age, cholesterol level, history of smoking, and BMI, among others, are all factors associated with the development of heart disease overtime. We can then use this information to train predictive models that can estimate an individual or groups ‘risk’ of developing heart disease in a given timeframe. This is a relatively simple example, but clearly outlines the basic steps of what is involved in this type of learning. Logistic regression (used in early cardiovascular epidemiologic studies like the Framingham Heart Study) is a basic form of supervised learning. Similarly, more advanced techniques like artificial neural networks (considered deep learning), can work with structured but more complex data such as images from echocardiograms or CT scans and learn to make automated measurements or diagnoses. For example, a powerful study by Zhang et al. utilized 14,035 pre-read and labeled echocardiograms from a large medical system to train an algorithm to recognize specific echocardiographic views, estimate ejection fraction and measure strain, as well as recommend 4 probabilistic diagnoses (the paper is available here).
Supervised learning can generally be broken into two main tasks – regression and classification. Regression models can learn from data in order to make predictions that are presented as continuous outcomes, such as the age person x is most likely to develop heart disease. Classification problems are focused on predicting discrete outcomes, such as will person x develop heart disease, yes or no.
Unsupervised Learning:
This area of machine learning utilizes ‘unstructured’ data, i.e. not labeled, to identify useful underlying patterns in the data. These patterns can then be assessed for relevance to specific questions. The two main unsupervised algorithm types are cluster modeling and dimensionality reduction.
Cluster modeling has been used with clinical data to try and identify unique groups of patients that may not be immediately notable without these algorithms. For instance, a seminal paper in the Cardiology literature by Shah et al., looked at a cohort of patients with heart failure and preserved ejection fraction (HFpEF) to try and identify unique clinical phenotypes among this seemingly heterogeneous cohort. The algorithm was able to separate the patients into three individual groups defined by unique characteristics they had in common. When researchers followed these patients forward in time, they found that the clusters had different levels of risk for major cardiovascular outcomes, indicating true clinical utility for evaluating the phenotypes individually (full paper here).
Dimensionality reduction takes complex, large datasets and narrows the field of features down into a small set of key features (principal components) associated with some characteristic of interest – it makes complex data more digestible.

Reinforcement learning:
This is a subset of machine learning that trains artificially intelligent agents and algorithms to learn through trial and error. Human feedback is given after each outcome during training. In a simple sense, this feedback comes in the form of a positive (reward) or negative consequence. Overtime, the system learns to maximize rewards by making beneficial choices.
Future posts will dive deeper into specific algorithms within each class. We will especially focus on Deep Learning (multi-layered artificial neural networks) which are responsible for advancing the field of AI (in healthcare and in general) by leaps and bounds. Convolutional neural networks excel at computer vision tasks, recurrent neural networks are very good at working with time-series data, and transformers can look at large chunks of input in a sequential manner and are the backbone of popular natural language processing systems like OpenAI’s GPT and Google’s Bard.
Please subscribe to our Newsletter for email notifications containing new posts as soon as they are published:

One thought on “What is Machine Learning?”