
This is a post that I have been planning to write for a while, but given the scope of change and constant expansion within this field it has proven difficult to stay up-to-date on the most current data models. That being said, large language models (LLM) are transforming all areas of medicine more quickly than any other technology has in the past, and covering this topic is very important to me. The following post is my review of the LLM landscape and how it is being integrated into the medical industry.

Introduction to Foundation Models
The term ‘foundation model’ was developed for a research paper by the Stanford Institute for Human-Centered Artificial Intelligence in 2021. It refers to a new wave of artificial intelligence (AI) models that learn from massive amounts of unlabeled data with self-supervised or unsupervised objectives. This allows them to process huge datasets to identify underlying patterns without significant oversight (though various types of fine-tuning and feedback, which does require significant human input, can increase accuracy and reduce hallucination). Their development hinges on recent advancements in deep learning neural network architecture and continually increasing computational power. Unlike previous AI and deep learning models designed for specific tasks (i.e. CNNs built to identify atrial fibrillation on a 12-Lead ECG), foundation models are general purpose and can be adapted to a wide range of uses, from communicating with patients via online portals to generating discharge summaries for patient hospitalizations.
LLMs are a specialized type of foundation model excelling in natural language processing (NLP) tasks. Essentially, they function as adept learners, ingesting and analyzing enormous text datasets. This data can encompass books, articles, code repositories, and even online conversations from social media sites. Through processing these vast troves of information, LLMs develop an understanding of the nuanced relationships between words and phrases. This empowers them to perform a multitude of functionalities within the NLP domain, such as:
- Creative Text Generation: LLMs can generate different forms of creative text formats, like poems, code, scripts, musical pieces, and even email.
- Machine Translation: LLMs can translate languages with high accuracy.
- Question Answering: LLMs can be instructed to answer questions in a comprehensive and informative way.
Large Language Model Development
Early LLMs relied on a special neural network architecture known as the recurrent neural network (RNN). Their strength lies in handling sequential data, which is very useful for NLP problems. RNNs process information in a chain-like fashion, utilizing special units like gated recurrent units or long short-term memory units. These units have internal mechanisms to control information flow. A cell state within the unit acts like a memory, storing information from previous inputs. Gates regulate how much information to forget, how much new information to add, and what context to pass on to the next step in the sequence. While powerful for their time, RNNs struggled with long-range dependencies in text and did not handle large sequences well. This limitation led to the rise of transformers, which is the structure of more powerful LLM architectures frequently utilized today.
Unlike RNNs, which process information sequentially, transformers can analyze the entire input sequence simultaneously using a powerful mechanism called ‘self-attention.’ Imagine laying out all the words from a sentence on a table. Self-attention allows each word to intelligently examine all the others at once, assessing their relevance and importance in the sentence. This approach empowers transformers to capture intricate relationships between words, regardless of how far apart they are within the sequence. Here’s a simplified breakdown of self-attention:
- Linear Transformations: Each word in the sequence is transformed into three vectors: a query vector, a key vector, and a value vector. Intuitively, the query vector represents what a word is looking for in the sequence, the key vector represents what other words have to offer, and the value vector holds the actual information of each word.
- Attention Scores: The query vector of each word is compared to the key vectors of all other words in the sequence. This comparison generates an attention score for each pair of words, indicating how relevant one word is to another.
- Weighted Values: The attention scores are then used to weight the value vectors of all the words in the sequence. Words with higher attention scores will have their value vectors contribute more significantly to the final output.
- The Attentive Representation: By summing the weighted value vectors, we obtain a new representation for each word. This representation incorporates information not just from the word itself but also from all the other relevant words in the sequence, thanks to the self-attention mechanism.
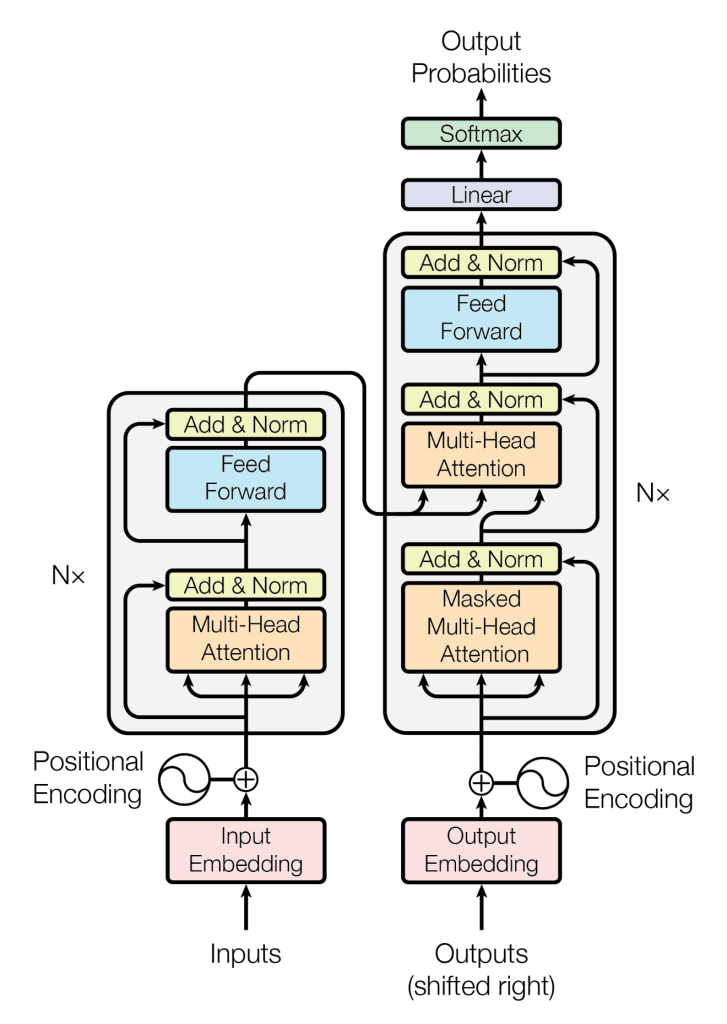
The building blocks of a transformer LLM are encoder layers. A typical transformer architecture consists of a stack of encoder layers, followed by optional decoder layers for tasks like generation or translation. Each encoder layer utilizes the self-attention schema discussed above to understand the relationships between words within the sequence, gradually building a contextual understanding of the entire input.
If you are interested in reading more about the fascinating development of transformers, then I would suggest the following article in Wired about the “Inventors of Modern AI” or the original research paper from Vaswani et al. at Google.
Types of Large Language Models
LLM neural networks are massive and complex. RNNs, convolutional neural nets and standard feedforward neural nets have parameter counts in the millions. Most common transformer based LLMs have parameter counts into the billions. Given their size and complexity, training these models is heavily resource intensive; most well known and highly performing models have been created by large technology corporations (Goolge, Facebook) or well-funded, rapidly motivated start-ups (OpenAI [significant backing by Microsoft], Anthropic). One of the earliest models to use the transformer technique was created by Google, and is known as the Bidirectional Encoder Representations from Transformers (BERT). BERT is open source and has been in use since 2018. There are specialized versions of this in public repositories that have been specifically trained to perform well in the biomedical and healthcare arenas, such as BioBERT and ClinicalBERT. Perhaps the most well known LLM family is the Generative Pre-trained Transformers (GPT). The earliest GPT model (GPT1) was also developed around 2018 by OpenAI, but its most famous product, ChatGPT, was released in 2022. The most recent iteration, GPT4, has been adapted into foundation models which can process both visual and language data with vastly expansive capabilities. Google has a foundation platform known as the Pathways Language Model (PALM) that has been fine-tuned with medical data. Other popular models are LLaMA from Facebook and Claude from Anthropic.
Large Language Model Training and Fine-Tunning
Pre-training serves as the cornerstone for LLM development. In this phase, LLMs are exposed to massive amounts of unlabeled text data, encompassing books, articles, code, and ‘web crawls’. This data fuels unsupervised learning, where the model identifies patterns and relationships within the language. Pre-training tasks like next-word prediction or sentence reconstruction further guide the LLM towards understanding language structure and meaning. The computational cost of pre-training is significant, requiring powerful hardware to handle the immense datasets and complex calculations involved. However, the benefits are substantial. Pre-trained LLMs boast improved generalization to new situations and faster fine-tuning on specific tasks due to their strong language foundation.
While the pre-training technique has allowed for the generation of advanced, robust algorithms that excel at many tasks, LLMs can sometimes struggle to generate factual outputs when faced with limited or very specific context – a problem that has been described as ‘hallucinating.’ One way to combat the process of hallucination, and to create task-specific or domain expertise, is the process of fine-tuning. Fine-tuning is achieved by utilizing a meticulously generated datasets containing labeled examples directly relevant to the desired domain and leverages supervised learning techniques often used in the training of more standard deep learning algorithms. During this process, a LLM is presented with the task-specific data and its predictions are assessed against known correct outputs, often referred to as ground truth labels. A loss function then calculates the discrepancy between these predictions and the ground truth. The crux of fine-tuning lies in minimizing this loss function through backpropagation, a powerful algorithm that helped pave the way for modern DL techniques. Backpropagation works by iteratively adjusting the weights within the LLM’s internal layers. These weights essentially dictate how strongly signals propagate through the model, ultimately influencing its final output. By backpropagating the loss function, the weights are fine-tuned, enabling the LLM to progressively enhance its ability to represent and manipulate language specifically within the confines of the target task.
In addition to standard fine-tuning with highly curated and labeled data-sets, a few other methods have evolved as well, such as reinforcement learning with human feedback (RLHF), retrieval augment generation (RAG) and n-shot prompting, to name a few.
Reinforcement Learning with Human Feedback
RLHF offers a compelling approach to training LLMs by incorporating human oversight into the learning process. Pre-trained LLMs generate outputs in response to prompts or tasks. Humans then evaluate these outputs based on pre-defined criteria, such as factual accuracy, helpfulness, or safety. This evaluation translates into reward signals for the RLHF system. Positive human judgment triggers positive reinforcement within the system, while negative evaluations result in penalties. The LLM continuously learns from this feedback loop, adjusting its internal parameters to favor generating outputs that consistently earn positive reinforcement. This ‘human-in-the-loop’ training approach offers several advantages. Firstly, RLHF promotes alignment with human values. By directly incorporating human judgment, it steers the LLM away from generating harmful or biased content. Secondly, RLHF enables task-specific fine-tuning. By focusing human feedback on a particular domain or objective, like crafting informative responses to patient queries about their medical care, RLHF can tailor the LLM’s capabilities for specific applications. Finally, RLHF has the potential to mitigate biases present in the vast datasets used to train LLMs. Human feedback can act as a corrective measure, prompting the LLM to move beyond potential biases in the training data. However, scaling human feedback collection and processing can be resource-intensive. Additionally, inherent subjectivity in human judgment can introduce inconsistencies into the feedback loop. So, while RLHF represents a significant step forward in shaping the development of LLMs, addressing scalability and subjectivity will be crucial to fully realize the potential of RLHF in the future of LLM development.
Retrieval Augmented Generation
Another process developed which helps to offset the hallucination problem is retrieval augmented generation (RAG). RAG addresses a key limitation of LLMs – their inherent reliance on static, internal knowledge representations. RAG tackles this issue by incorporating factual data retrieval from external knowledge sources. This three-step process involves: (1) Retrieval: the LLM identifies relevant information needs within a prompt. (2) Retrieval: the system retrieves factual documents from a knowledge source based on the identified needs. (3) Augmentation: the retrieved documents are incorporated and processed alongside the original prompt to inform the LLM’s generation process. This augmentation step allows RAG-powered LLMs to access up-to-date information and ground their responses in factual evidence, enhancing the accuracy, reliability, and explainability of their outputs. Compared to traditional LLMs, RAG offers a promising approach for knowledge-intensive tasks and real-world applications where access to current and verifiable information is crucial.
Large Language Models in the Healthcare Setting
Given their expansive capabilities, LLMs are poised to significantly impact the healthcare landscape and there is already a growing literature base reviewing these models in a variety of settings, including administrative, clinician-facing and patient-facing tasks. Foundation models and LLMs can analyze electronic medical data, unstructured medical notes, imaging files, and numerous other data to identify patterns and correlations that might aid doctors in diagnosing diseases more accurately. LLMs should play a crucial role in patient communication; by translating complex medical jargon into plain language, they can empower patients to better understand their conditions and treatment options. Additionally, LLMs can be used to create chatbots that answer patients’ questions and address concerns 24/7, improving patient education and overall satisfaction. There are a number of review papers covering other areas within the healthcare system that have been impacted by these models:
- Coding for hospital and practice reimbursement
- Translation of educational resources and medical notes from one language to another
- Clinical decision support for physicians
- Hospitalization and clinical visit summarization (drafting discharge summaries and after visit plans)
- Ambient listening and medical note drafting (medical scribe services)
- Insurance authorization correspondence
- Patient facing chatbots
Because these models require significant time, computing resources and expertise to develop, there has been a shift towards hospital systems partnering with large technical corporations (Microsoft, Google, Amazon) to bring in these capabilities, either directly or through their EHR systems. There are also a number of startup companies that are trying to compete with the larger corporations in certain key areas (Glass Health, Abridge, HippocraticAI). This evolution could drastically change the healthcare landscape.
In the midst of all of the hype, it is important to remember that LLMs are currently being used as tools, not replacements, for human expertise. Clinicians should remain centered at the forefront of decision-making, utilizing LLMs to augment their knowledge and efficiency. As LLM technology continues to evolve, responsible development and implementation will be key to unlocking its full potential in transforming healthcare for the better.
Links to Medical Reviews of LLMs
- Multimodal Generative AI for Precision Health: Link
- Towards Generalist Biomedical AI (Goole PALM): Link
- Large Language Models in Medicine: The Potentials and Pitfalls: Link
- Artificial intelligence: revolutionizing cardiology with large language models: Link
- Large language models encode clinical knowledge: Link
Please subscribe to our Newsletter for email notifications containing new posts as soon as they are published:
